Os desafios de criar uma arquitetura moderna de dados
Olá,
é quase certo que você escute de qualquer empresa no mercado hoje que possuem um cultura orientada a dados ou que estão em busca disso, a expressão em inglês Data-Driven. Porém, não são todas que conseguem de fato assim como é com a tal transformação digital que ainda escutamos por ai. Talvez, não estamos sabendo diferenciar a fome da vontade de comer. A fome é uma necessidade do nosso corpo em busca de nutrição para nos dar poder de realizar nossas atividades. A vontade de comer é um mecanimos mais cerebral, por exemplo, você não precisa comer um chocolate mas o fato de comer vai lhe causar uma recompensa cerebral relacionada ao prazer.
E qual a relação disso com o nosso mercado atual? Por conta dessa necessidade de orientar o negócio através de dados estamos nos deixando vencer pela vontade de comer pois são criadas estruturas e processos para se trabalhar com dados ainda sem entender muito bem quais problemas queremos resolver. Ao invés disso, precisamos aprender a observar o ambiente, entender suas dores e partindo disso definir aquilo que precisa ser feito e elaborar um plano para execução. É preciso ter fome anter de ter vontade de comer.
Sabendo-se disso existem alguns tópicos que precisamos saber responder e como abordar para ter uma solução de sucesso na área de dados qie vamos discutir a seguir. Os tópicos não estão em ordem de prioridade ou algo do tipo pois acredito que eles mudam muito de prioridade entre empresas mas olharia sempre com carinho primeiro para a estratégia de dados da empresa.
Estratégia de dados

A estratégia de dados é a visão de como a empresa vai coletar, armazenar, gerenciar, compartilhar e usar dados. Dependendo do tamanho e momento da empresa a estratégia de dados vai estar mais alinhada a descoberta do produto que estão construindo ou do crescimento de um negócio já existente. Assim como, pode estar quebrada em silos ou pode ser uma estratégia única. Podemos quebrar esse assunto em três tópicos que veremos a seguir.
Inovação
A inovação através dos dados pode ser vista de duas maneiras, na primeira, ela entra como suporte observando a real inovação e dando todo o suporte através de números que ele está indo bem ou mal, por exemplo, a área de marketing analytics que está tão em evidência. Outra visão é com o dado sendo o protagonista da inovação, existem muitos dados espalhados por ai e sem uso e conhecimento em cima deles, inovar pode ser transformar todos esses dados em algo novo, por exemplo, com a inovação do sequenciamento do DNA agora é possível inovar neles com algoritmos que são capazes de inovar na área de saúde como estamos vendo agora na pandemia.
Resolver o problema dos usuários
Através dos dados podemos obervar o comportamento dos usuários e entender quais processos precisam melhorar dentro da nossa solução para levar uma melhor experiência a ele. Por exemplo, hoje temos uma grande quantidade de FinTechs que surgiram e em sua maioria o processo de cadastro é todo feito via aplicativo no celular com diversas etapas até que no final das contas você tem ou não acesso ao produto delas. Transformar toda essa jornada em dados pode levar sua empresa a uma melhor conversão dessa massa da possíveis clientes pois você pode descobrir que parte significante deles tá tendo problema em uma fase de captura de dados de documentos pois estão mandando foto do RG plastificado o que atrapalha o algoritmo que identifica o RG e captura as informações dele.
Risco e regulamentações
Muito legal o que vimos até agora das possiblidades que os dados nos fornecem mas existe também todo um risco envolvido nisso. No Brasil e mundo regulamentações existem e vão continuar a existir para cuidar dessas informações, por exemplo, a LGPD aqui no Brasil e a GDPR na Europa que estão preocupados com o uso de dados do cidadão com foco em garantir o direito a privacidade deles e causando multas a quem não seguir suas regulamentações.
Governança de dados

No tópico anterior terminamos falando de risco e regulamentações quando se trabalha com dados e uma forma de endereçar esse problema é com a governança de dados que é um item essencial para quem está construindo uma plataforma de dados. Podemos dividir os desafios da governança de dados em duas frentes de gestão em que uma falamos das informações e da outra das pessoas.
Gestão do conhecimento
Na gestão do conhecimento estamos tratando sobre os processos envolvidos com relação a informação. Na prática estamos falando de conseguir mapear todos os dados que estão na custódia da empresa, partindo disso construir um catálogo de dados dando detalhes sobre o que são esses dados e suas classificações. Isso é muito importante pois é extremamente necessário para conseguir aplicar na prática os controles da LGPD, por exemplo. Além disso, precisamos ter controle do dado em movimento, ou seja, um dado nasce em um determinado ponto e passa através de diversos sistemas sendo transformado ou não para atender alguma outra necessidade, o controle de por onde essa dado passou também precisa ser monitorado. A gestão do conhecimento vai ainda mais além mas isso já apresentado é algo muito complicado de se ver funcionando na prática pois vai dar um bom trabalho.
Gestão de acesso
Agora que você conhece os dados pela gestão do conhecimento é hora de trabalhar o controle de acesso aos mesmos. Na gestão de acesso vamos trabalhar nos contratos de acesso a informação e toda a orquestração técnica para gerir esse controle de acesso que hora vão ser pontuais por um determinado tempo ou quantidade de vezes ou vai ser algo sem data limite. Esse controle de acesso vai poder ser individual ou de grupos.
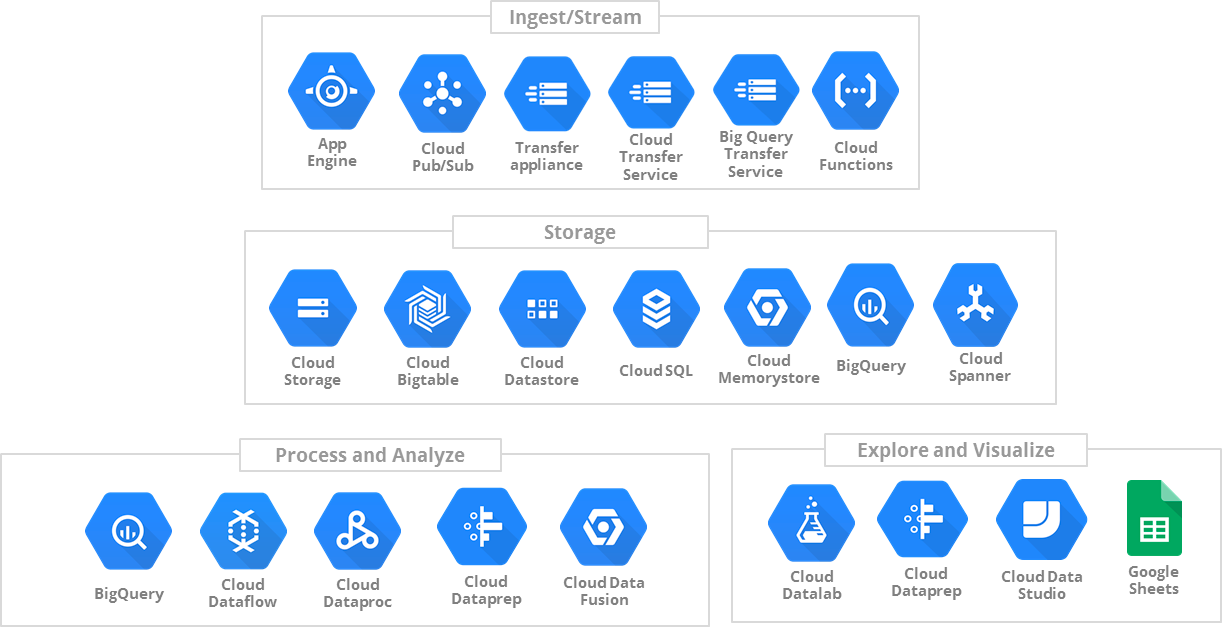
Plataforma de dados

Na plataforma de dados é onde vamos endereçar tecnicamente tudo que foi dito até aqui. Uma opinião pessoal, é preciso tratar essa área como uma área de produto pois se ficar no modelo mais clássico de ficar recebendo demandas para montar visuzalizações e analises de ponta a ponta o time vai precisar crescer absurdos em termos de pessoas se tornando um gargalo e não chegando na tal cultura orientada a dados que todos querem. Nos tópicos a seguir vamos falar sobre as partes de uma plataforma de dados e como podemos resolver os problemas dessas áreas.
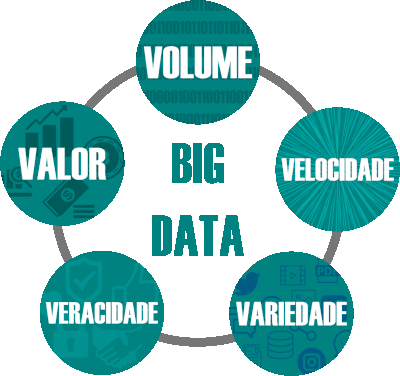
Antes disso, vamos lembrar algo muito importante do universo de dados que são os 5 V’s do Big Data: Volume, Velocidade, Variedade, Veracidade e Valor. O volume de dados é geralmente onde começamos a desenhar e planejar nossa plataforma de dados apesar de toda incerteza que existe sobre isso pois nem sempre é claro o quanto o produto vai crescer o que direciona para o próximo V. A qual velocidade cresce e o produto e o quanto o quanto esse crescimento reflete na velocidade que os dados são criados e manipulados e como valos lidar com isso pois eles podem todos vir de uma mesma fonte mas também podem vir de vários locais diferentes conectando ao próximo V. Hoje, produtos se tornaram sistemas extremamente complexos com diversas aplicações, banco de dados e afins trazendo uma variedade enorme de dados e seus formatos, ser capaz de lidar com isso tudo é um grande desafio para a construção da sua plataforma. Com toda essa complexidade de como nascem os dados vem o desafio de ao trazer eles para sua plataforma é como garantir a veracidade dos mesmos pois são muitos dados e diversos. Por fim, dado por si só é apenas um custo de infraestrutura e para que esse custo tenha um retorno é preciso trabalhar no valor deles fazendo pergunta certas a esse enorme conjunto de dados criando analises, visualizações e modelos que agreguem valor ao negócio.
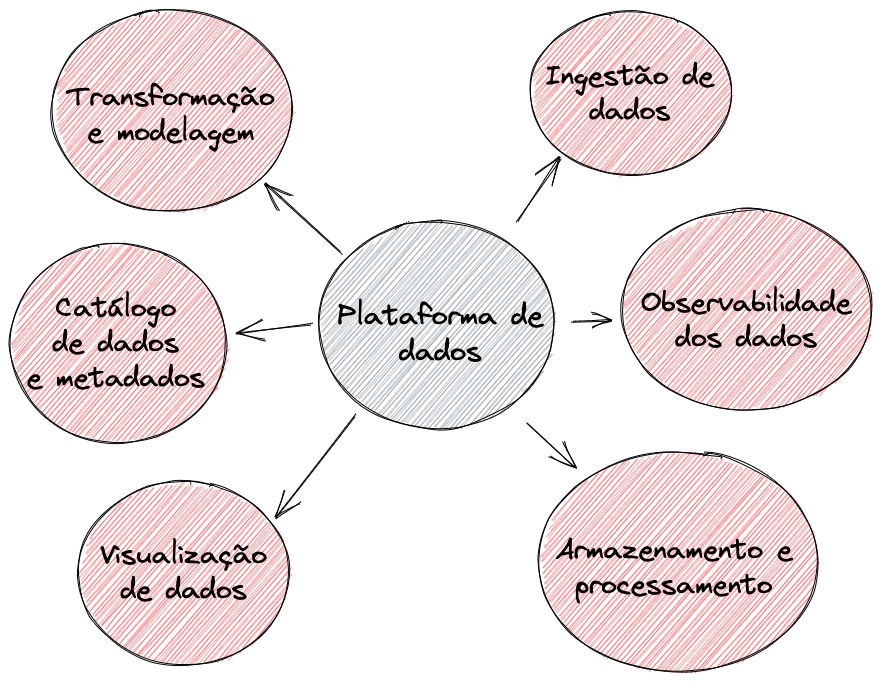
Ingestão de dados

Essa é uma das camadas mais complexa na minha opinião de resolver os problemas de maneira escalável de uma plataforma de dados. Imagine que aqui você tem que normalizar toda a complexidade de tipos de dados do ecossistema que você está atuando em algum padrão que você vai trabalhar na sua plataforma. Outra questão é que podemos ter dois modos de ingestão de dados na nossa plataforma: 1) ativa: de alguma maneira você executa tarefas agendadas na sua plataforma que vai coletar dados de algum local, por exemplo, coletar dados do Google Analytics; 2) passiva: os dados de alguma forma chegam até você e sua responsabilidade é apenas processar eles, por exemplo, alguma integração de webhooks.
Entrando em mais detalhes do motivo das complexidades nessa parte, podemos fazer algumas perguntas para entender ela:
Como fazemos para a escalar ingestão de dados sem ser limitado a quantidade de pessoas no time?
Imagine que para toda nova aplicação na arquitetura da seua empresa uma pessoa de engenharia de dados precise criar um código customizado para que os dados gerados por ele venham para o seu Data Lake. Isso não se torna viável dado o que vemos hoje no mercado com empresas com diversas aplicações em produção para construir o produto da empresa. Então, é preciso que nesse problema se tenha mentalidade de produto e construa alguma abstração que resolva esse problema de maneira escalável.
Como lidar com os diversos formatos de dados e variações dos mesmos?
Como a ideia das aplicações modernas é que cada uma use as melhores tecnologias para o seu contexto pode ser que você tenha ambientes caóticos que existem mais três banco de dados diferentes em produção, mais de um sistema de troca de mensagens e por ai vai. Também ao longo do ciclo de vida dessas aplicação que hoje uma determinada tabela tinha cinco colunas amanhã ela pode ter sete, o que fazer?
Armazenamento e processamento

Unido ao problema de ingestão você tem o desafio de entender como aquele dado recebido deve ser processado e armazenado. Obrigado LGPD e afins que tornaram a nossa vida ainda mais fácil nesse sentido dado que agora temos mairores rigores de segurança e privacidade de dados a serem tratados nessa parte. Como decidir se os dados vão ser armazenados em arquivo em alguma solução de arquivos tipo s3 da AWS ou salvo direto no Redshift? Vou processar esses dados com Spark ou no Airflow?
Transformação e modelagem
Legal, os dados estão agora no Data Lake ou seja lá outra coisa que você fez e está usando para armazenar os dados armazenados na camada de ingestão mas isso até o momento só é custo de infraestrutura. Precisamos começar a transformar esse custo em valor e é nessa camada que o processo começa refinando os dados brutos coletados e começando a serem transformados em modelos de dados que serão aproveitas por cientista de dados para construção de modelos de aprendizado de máquina ou visualização de dados mais inteligentes que vão permitir pessoas de negócio tomarem ações de forma mais rápida e inteligente conectando ao próximo item.
Visualização de dados
Com os dados modelados é só agora na sua ferramenta de visualização de dados escolher os atibutos e um gráfico que melhor represente sua amostra e começar suas analises. Além disso, é importante que a ferramenta tenha capacidade de criar alertas para determinadas configurações de gatilho e suporte para métricas que é possível trabalhar com previsibilidade ter.
Observabilidade dos dados

Hoje uma operação de dados é tão crucial quanto a operação do transacional do negócio, principalmente quando existe uma dependência do transacional dela, por exemplo, um sistema de fraude. Falhas nos dados podem comprometer uma operação toda pois essas informações podem estar sendo usadas para alguma regra de negócio. Por isso, é muito importante cuidar da observabilidade dos dados assim como fazemos das aplicações. Então, é preciso criar mecanismos para saber o quanto os dados são recentes na sua base, se estão completos, não tem nada fora de um valor esperado, muitos valores nulos e outras coisas mais. Hoje, temos ferramentas de código aberto no mercado que ajudam nisso e também empresas que estão atacando esse problema.
Catálogo de dados e metadados

Se você trabalha na área de dados a um certo tempo é bem provável que tenha passado pela situação de ter que fazer uma SQL e pra isso precisar conversar com diversas pessoas diferentes para entender os dados de uma determinada tabela e seus atributos. Isso é um problema bem comum pois documentação de sistemas como bem sabemos já é bem complicado das pessoas terem o hábito de fazer, quem dirá do banco de dados e afins. Só que com o protagonismo da área de dados nos últimos tempos com a disciplina de ciência de dados e regulamentações como GDPR e LGPD essa documentação passou ser um requisito. Existem algumas formas de resolver tanto com ferramentas de código aberto quanto empresas que vão fornecer uma solução.
Pessoas
Acredito que essa é a parte mais complicada de todas. Criar um time para atacar todos esses problemas tem se tornado um desafio enorme nos tempos recentes pela alta procura de pessoas no mercado com habilidades para resolverem esses problemas e falta de pessoas com uma boa experiência no assunto. Além disso, como organizar essas pessoas em times e garantir que elas se sintam bem na atividade proposta. Outro desafio é que todo dia surge um nome novo de cargo nessa área e ai vem a síndrome da grama do vizinho é mais verde, por mais que as pessoas façam exatamente a mesma coisa em empresas diferentes com cargos diferentes isso já é suficiente para plantar a pulga atrás da orelha. Outro problema com o crescimento da área é o crescimento da quantidade de soluções para resolver os problemas dela e com isso gerenciar o que estudar e testar, e fazer a gestão da modinha na sua arquitetura. Somo humanos e curiosos por natureza, nossa evolução se deu pela curiosidade e não devemos tolir isso mas sim garintir que ela ocorra de maneira saudável.
Referências
- “What exactly is a data-driven organization?”: https://www.cio.com/article/3449117/what-exactly-is-a-data-driven-organization.html
- “Você sabe o que é uma fintech? Veja 9 exemplos”: https://fintech.com.br/blog/fintech/o-que-e-fintech/
- “Proteção de Dados - LGPD”: https://www.gov.br/defesa/pt-br/acesso-a-informacao/lei-geral-de-protecao-de-dados-pessoais-lgpd
- “General Data Protection Regulation”: https://gdpr-info.eu/
- “5V’s of big data via cloud computing: uses and importance”: https://www.researchgate.net/profile/Mohammad_Quasim2/publication/333171951_5_V'S_OF_BIG_DATA_VIA_CLOUD_COMPUTING_USES_AND_IMPORTANCE/links/5cdeae69a6fdccc9ddb6da39/5-VS-OF-BIG-DATA-VIA-CLOUD-COMPUTING-USES-AND-IMPORTANCE.pdf
- “Google Analytics”: https://analytics.withgoogle.com/
- “AWS s3”: https://aws.amazon.com/pt/s3/
- “Amazon Web Services”: https://aws.amazon.com/pt/?nc2=h_lg
- “AWS Redsifht”: https://aws.amazon.com/redshift/
- “Apache Spark”: https://spark.apache.org/
- “Apache Airflow”: “https://airflow.apache.org/
- “What is a data lake?”: https://aws.amazon.com/big-data/datalakes-and-analytics/what-is-a-data-lake/
- “SQL”: https://pt.wikipedia.org/wiki/SQL



Comments ()